Dissecting Relu: A desceptively simple activation function
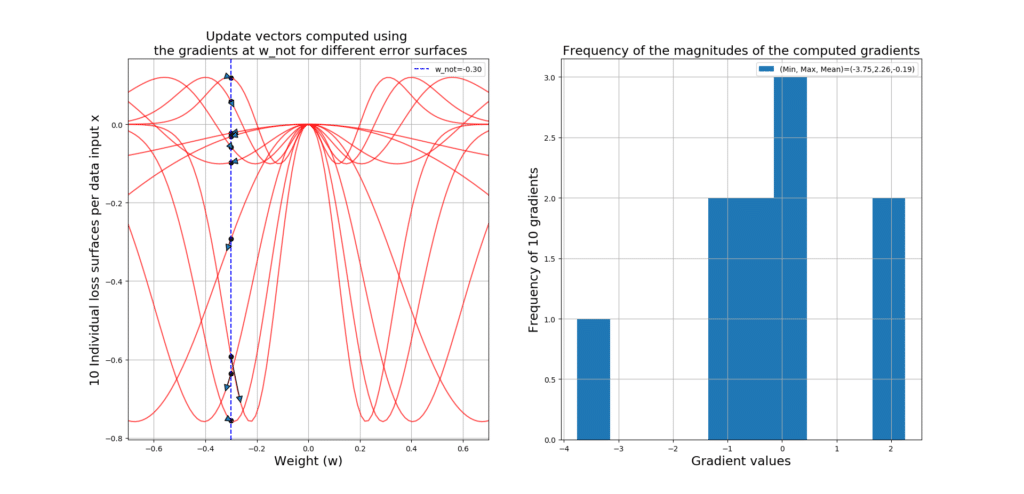
What is this post about? This is what you will be able to generate and understand by the end of this post. This is the evolution of a shallow Artificial Neural Network (ANN) with relu() activation functions while training. The goal is to fit the black curve, which means that the ANN is a regressor! …
Dissecting Relu: A desceptively simple activation function Read More »