

An Interview with Prof. Karl Friston
Karl Friston is a theoretical neuroscientist and authority on brain imaging. He invented statistical parametric mapping (SPM), voxel-based morphometry (VBM)

A Gentle 101 Talk on Artificial Neural Networks
What is this post about? In this super gentle 101 talk given at the Insight Centre for Data Analytics at
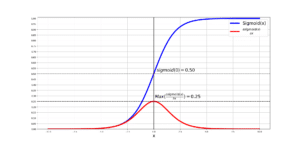
The Backpropagation Algorithm-PART(1): MLP and Sigmoid
What is this post about? The training process of deep Artificial Neural Networks (ANNs) is based on the backpropagation algorithm.

Dissecting Relu: A desceptively simple activation function
What is this post about? This is what you will be able to generate and understand by the end of

An interview with Prof. Mikhail Belkin
We never Had Truly Understood the Bias-Variance Trade-off!!! In this interview with Prof. Mikhail Belkin, we will discuss his amazing

Reconciling modern machine learning practice and the bias-variance trade-off
What is This post about? The interview with the lead author of the paper: Prof. Mikhail Belkin Together we will

An interview with Prof. Tom Mitchell
“There are a lot more papers written than there are widely read!” (Tom Mitchell) Prof. Tom Mitchell is one of
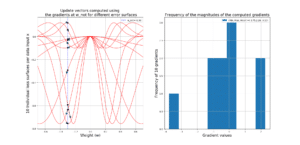
Stochastic Approximation to Gradient Descent
What will you learn? The video below, delivers the main points of this blog post on Stochastic Gradient Descent (SGD):

Back-propagation with Cross-Entropy and Softmax
What will you learn? This post is also available to you in this video, should you be interested 😉 https://www.youtube.com/watch?v=znqbtL0fRA0&feature=youtu.be