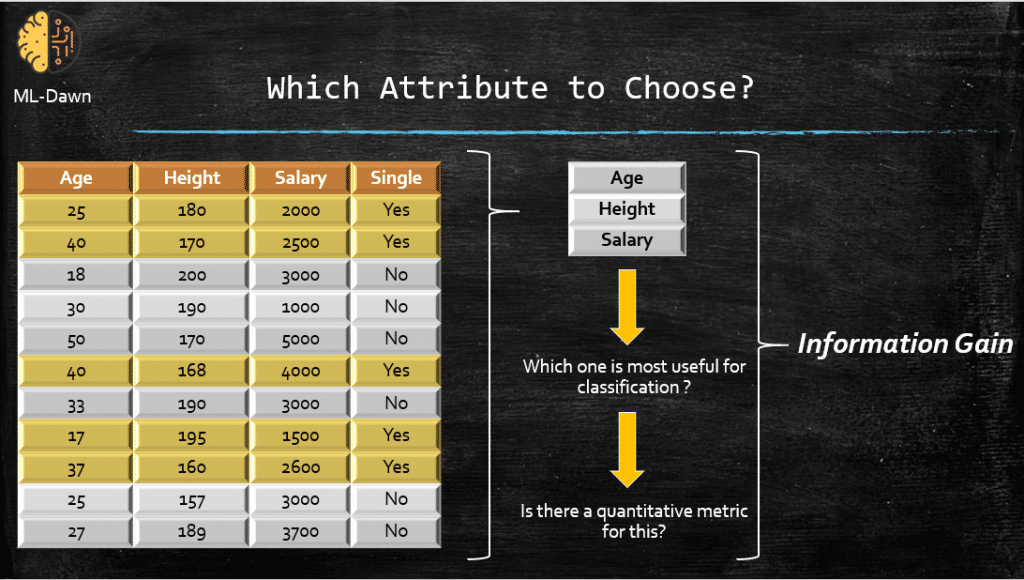
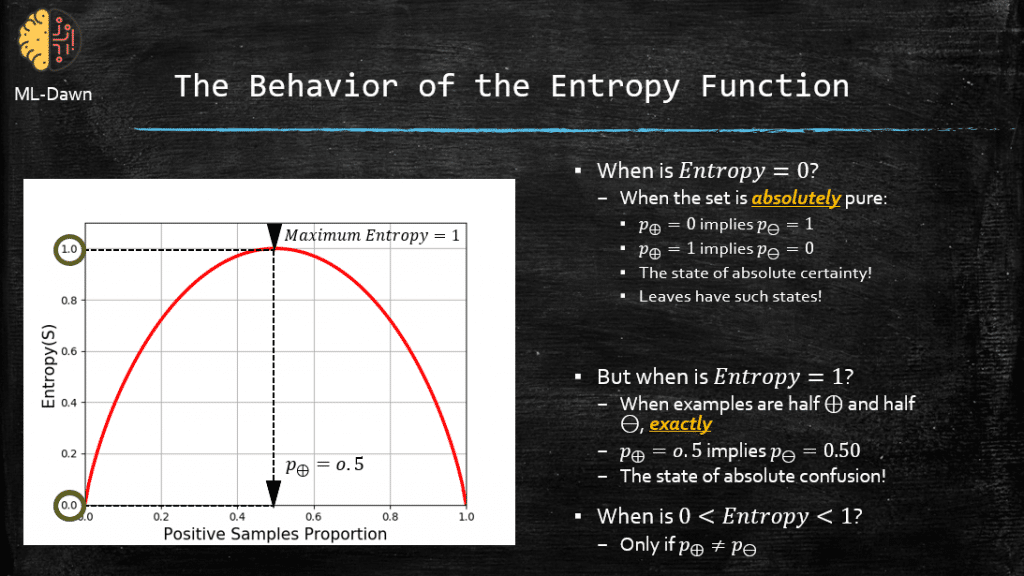
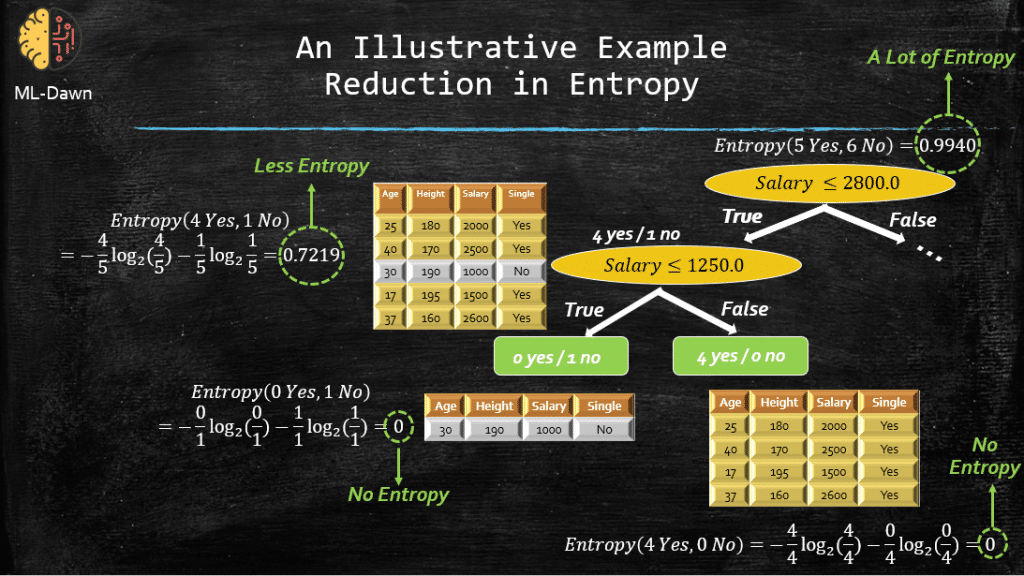
On the horizontal axis we can see the proportion of positive examples (i.e., 1 – Proportion of negative examples) in the set S. On the vertical axis we can see the Entropy of the set S. It seems that this function has indeed a maximum, and it hits 0 ONLY in 2 cases.
In a binary classification problem, when Entropy hits 0 it means we have NO entropy and S is a pure set. So, the members of S are either ALL positive or ALL negative. This is where we have absolute certainty and if you remember in our last post, the leaves of a decision tree are in such state of purity and certainty.
The entropy function for a binary classification has the maximum value of 1. This is the state of utter confusion and highest disorder and entropy. This happens when our set S is EQUALLY divided into positive and negative examples. Meaning that P(+) = 0.5 which automatically implies that P(-) = 0.5.
Finally, in a binary classification problem, if P(+) and P(-) are NOT equal, for example P(+) = 0.7 and P(-) = 0.3, the Entropy is ALWAYS between 0 and 1.
I can actually prove to you that the Entropy for a binary classification problem has a maximum of 1 If and Only If p(+) = P(-) = 0.5. In order to do this, we will have to take the partial derivative of Entropy with respect to one of the proportions (say P(+)), and set it to 0. Then, when we find the critical value for P(+) we can easily find P(-) as we know that: P(+) = 1 – P(-). Finally, by plugging in these critical values for P(+) and P(-) in the Entropy function, we can find the maximum value of the Entropy in the binary classification problem. Below, you can see all the math involved: