

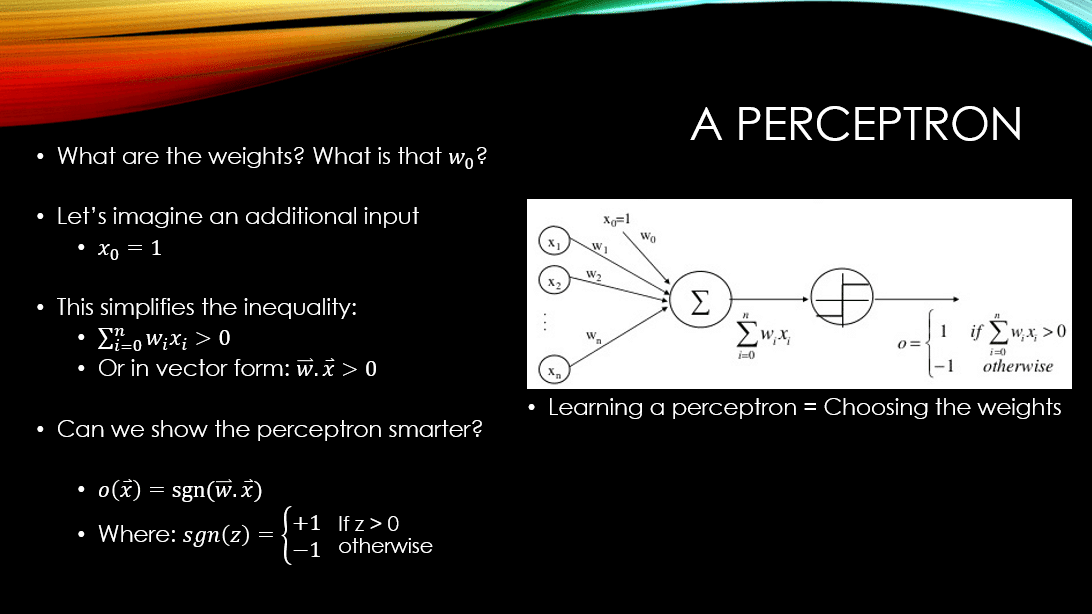
Imagine we have a binary classification problem at hand, and we want to use a perceptron to learn this task. Moreover, as I have explained in my YouTube video, a perceptron can produce 2 values: +1 / -1 where +1 means that the input example belongs to the + class, and -1 means the input example belongs to the – class.
Obviously, as we have 2 classes, we would want to learn the weight vector of our perceptron in such a way that, for every training example (depending on whether it belongs to the + / – class), the perceptron would produce the correct +1 / -1. So, in summary:
What are we learning? The weights of the perceptron
Is any weight acceptable? Absolutely not! We would want to find a weight vector that makes the perceptron produce +1 for the + class, and -1 for the negative class
NOTE: You define which class is + and which is -! Moreover, you can train the perceptron and find a weight vector that produced +1 for – class and -1 for + class! It doesn’t really matter, as long as the perceptron can generate 2 different outputs for the instances that belong to class + / -. This is how you can measure the separating, and classification power of the perceptron.
So, we are talking supervised learning here, which means that we know the true class labels for every training example in our training set. As a result, in the perceptron training rule, we would initialize the weights at random and then feed the training examples into our perceptron and look at the produced outputthat can be either +1 or -1! So, we would want the perceptron to produce +1 for one class and -1 for the other. After observing the output for a given training example, we will NOT modify the weights unless the produced output was wrong! For example, if we want to produce +1 for + class and -1 for the – class, and if we fed an instance of the – class and the perceptron returned +1, then it means that we need to modify the parameters of our network, i.e., the weights. We will keep this process, and we will keep iterating through the training set as long as necessary until the perceptron classifies all the training examples correctly.
How do we update the weights? Is there some sort of mathematical rule? Yes, indeed there is! One such rule is called the perceptron training rule!
At every step of feeding a training example, when the perceptron fails to produce the correct +1/-1, we revise every weight wi associated with every input xi, according to the following rule:
wi = wi + Δwi
where:
Δwi = η(t – o)xi
The variables in here are described as follows:
: This means how much should I change the value of the weight
. In other words, this is the amount that is added to the old value of
: This is the learning rate, or the step size. We tend to choose a small value for this, as if it is too big we will never converge and if it is too small, we will take for ever to converge to the correct weight vector and have a decent classifier. This step size, simply moderates the weight updates just so the updates would not make an aggressive change to the old values of the weights.
: This is the ground truth label that we have for every training example in our training set. For a classification task, as we know tha our perceptron can produce either +1 or -1, then we will consider
: This is the output of our model, which in this case can be either+1 or -1.
: This is the
dimension of our input training example
, which is connected to the weight



Author: Mehran
Dr. Mehran H. Bazargani is a researcher and educator specialising in machine learning and computational neuroscience. He earned his Ph.D. from University College Dublin, where his research centered on semi-supervised anomaly detection through the application of One-Class Radial Basis Function (RBF) Networks. His academic foundation was laid with a Bachelor of Science degree in Information Technology, followed by a Master of Science in Computer Engineering from Eastern Mediterranean University, where he focused on molecular communication facilitated by relay nodes in nano wireless sensor networks. Dr. Bazargani’s research interests are situated at the intersection of artificial intelligence and neuroscience, with an emphasis on developing brain-inspired artificial neural networks grounded in the Free Energy Principle. His work aims to model human cognition, including perception, decision-making, and planning, by integrating advanced concepts such as predictive coding and active inference. As a NeuroInsight Marie Skłodowska-Curie Fellow, Dr. Bazargani is currently investigating the mechanisms underlying hallucinations, conceptualising them as instances of false inference about the environment. His research seeks to address this phenomenon in neuropsychiatric disorders by employing brain-inspired AI models, notably predictive coding (PC) networks, to simulate hallucinatory experiences in human perception.



Responses
Computing Each of these Derivatives Separately