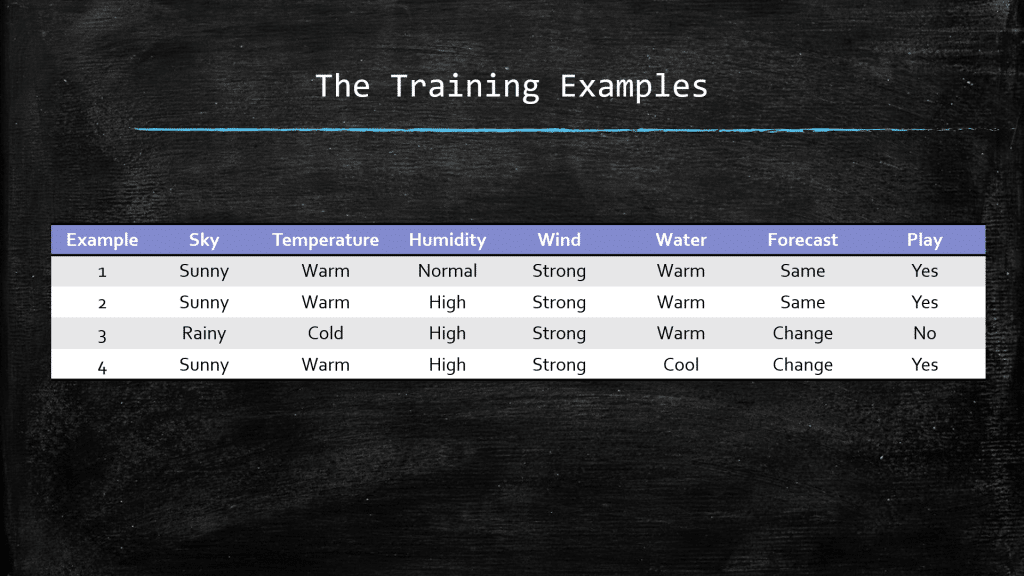
Remember that we want to learn the concept of play so we can understand what is the playing habit of Joe. Meaning in what type of a day would he play golf?! all we have at hand is the limited and yet valuable set of training examples (A small set of the instance space: All possible days!). Let’s follow the algorithm:
- We start by the most specific hypothesis, meaning the most limited and constrained one in H:
h = <Ø,Ø,Ø,Ø,Ø,Ø>
- Now we walk through the training examples. Upon observing the first training example
x1 = (Sunny, Warm, Normal, Strong, Warm, Same)
- which happens to be a positive example (i.e., Play = Yes), we can see that h is too specific to be satisfied by this training example (or for any positive training example for that matter). So the next step is to replace every constrained in h that are not satisfied by x1, with the NEXT more general constraint that could make h satisfiable by this training example. So, NONE of the Ø constraints can be satisfied by this training example, so what is the next more general value for each one of the Ø constraints that could make h, just general enough to have classified x1 as positive? One might suggest: “replace all of the Ø constraints with the question mark constraint ?“. The answer to this BIG step of generalization is that, yes, the new h will definitely classify x1 as positive. But as you can imagine, it classifies literally EVERYTHING else as positive as well! Now this is definitely a catastrophe as h will lose any discriminatory functionality which is needed for building a classifier in the first place. So, we need to generalize h just enough to classify x1 as positive! So, another solution is to literally, replace every Ø constraint with its corresponding attribute value in x1. This makes h satisfiable by x1:
h = <Sunny, Warm, Normal, Strong, Warm, Same>
- Now, this new h is a little bit less specific than the previous h, in that there is at least 1 training example that can satisfy it (i.e., x1). But it is still pretty limited, as it will classify anything else as negative, which is again catastrophic! We need more generalization as we will see in the following.
- Our next training example, which happens to be a positive example again, is:
x2 = (Sunny, Warm, High, Strong, Warm, same)
and we can see that there is only 1 value in x2 that prevents x2 from satisfying our current hypothesis h, and that is the value for the attribute “Humidity”! Our most updated hypothesis h, requires that the “Humidity” level be “Normal” whereas in x2 , it is High. However, all the other attribute values in x2 can satisfy their corresponding constraints in h. So, we need to do something with the current constraints on “Humidity” in h. The constraints on “Humidity” was Ø at first, then we had to change it to “Normal” to adapt to our first observed training example x1. And now, x2 has the value “high” for “Humidity”!
- So, what sort of constraint should we have for “Humidity”, so that it could be satisfied by x2 and yet be satisfied by the first example x1? Yes! The answer is the question mark constraint “?”, which is satisfiable with both “Normal”, and “High”, found in x1, and x2. So the next more general hypothesis is:
h = <Sunny, warm, ?, Strong, Warm, Same>
Upon seeing the third training example, which happens to be a negative example, the Find-S algorithm simply ignores it and makes no change to the currently found hypothesis. However, notice that h is already classifying this negative example x3 as negative (i.e., h(x3) = 0), meaning that x3 fails to satisfy h, so no change on h is needed!
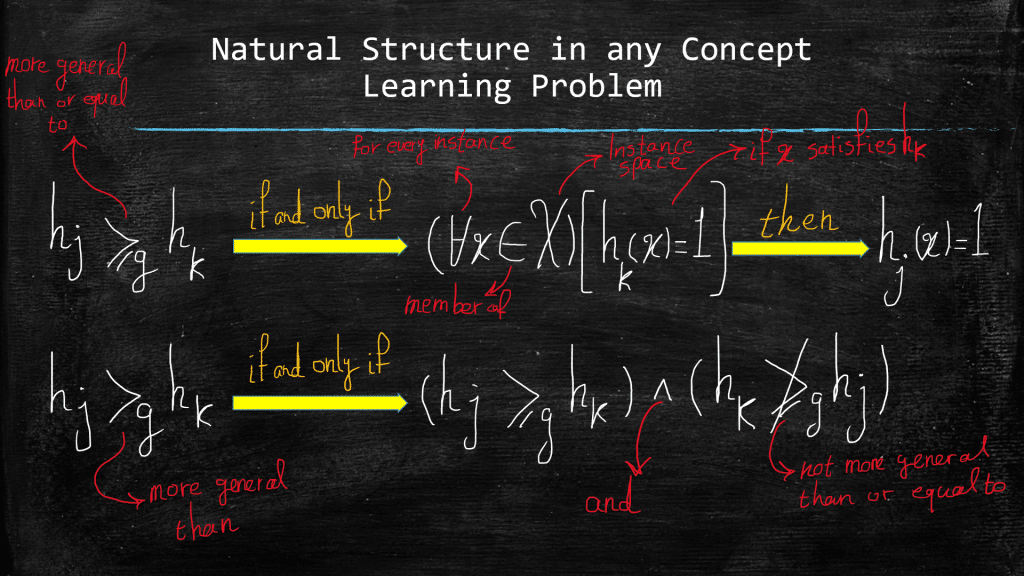
IMPORTANT: Note that at any stage of our search in Find-S algorithm, the obtained hypothesis h, is the most specific hypothesis that is consistent with the observed positive example. Remember that we are seeking the hidden desired hypothesis c in the hypothesis space, and we know that c is definitely, 100%, consistent with the positive training examples, so target hypothesis c (i.e., the target concept) is for sure more-general-than-or-equal-to h. Remember that the target concept c will never cover the negative examples (i.e., negative examples cannot satisfy c), so since we just established that:
c ≥g h
Then those negative examples cannot satisfy h either, as we know that c encompasses h. Finally, upon arrival of the fourth example x4:
x4 = (Sunny, Warm, High, Strong, Cool, Change)
We can see that the last 2 values “Cool” and “Change” fail to satisfy our current h! So, h needs to evolve to the next more general hypothesis that is:
h = <Sunny, Warm, ?, Strong, ?, ?>







Responses