

As you remember, we said that the update rule for a given weight, , (generally speaking) is:
where:
And we emphasized that is called the gradient of our error,
, with respect to our parameter,
. Finally, we talked about
which is our learning rate (a.k.a., the step size). Now it is time to consider a quite simple neural network, with some weights to be learned, and an error function of choice to be minimized. Consider the simple neural network below:
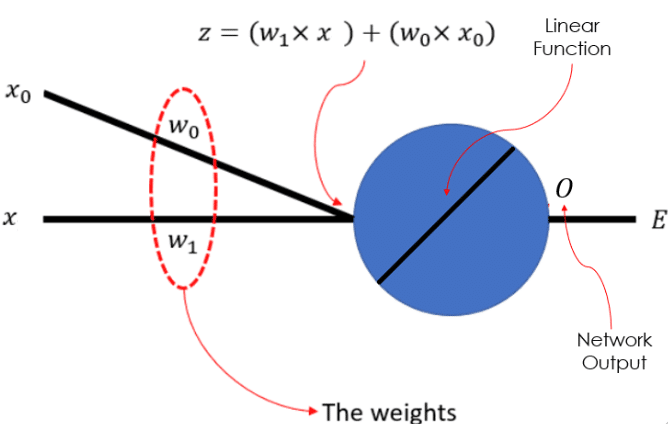
In this network, we have a 1-dimensional input data, , with a bias unit,
, that is always equal 1, by definition. We have 2 sets of weights
and
, which we are trying to learn using gradient descent. The actual big blue circle is a linear neuron and
represents the output of the neural network. As you can see, the input data and the weights are linearly combined to make
, which is also called the pre-activation of the neuron. We will further define an error function,
, that we are trying to minimize by learning an appropriate set of values for our weights. Let’s define an error function:
You notice that this error is a function of the weight vector, which is a vector of all the weights in our neural network to be learned. So, for every input training data , in our training set
, we generate the output of our model, that is
. Then we compute the squared difference between this output and the desired output
. We compute this squared difference for every input data, and sum them all up and finally divide it by 2, to compute the total error across the entire training set. So, you can see that minimizing this error across the entire training set, means that for every input data
, the output of our model
is getting quite close to the target value
, which our ground-truth.
One a side note, there is a very good reason why we have the square operation and the division by 2, in this definition of error. I have explained this in details in my course “The Birth of Error Functions in Neural Networks”. Click here to enroll (It is Free!)
So, now we need to take the derivative of our error function with respect to every one of the weights in our network. This will be the gradient of the error with respect to the weights. As a result, for every weight  in our network, the derivative of the error
in our network, the derivative of the error  with respect to that weight, which is denoted as
with respect to that weight, which is denoted as  , is computed as follows:
, is computed as follows:

Please note that , means the
dimension of the
training example.
In other words, if a weight connected to the
dimension of the input,
, in the derivations above.
Now we have the gradient and it is time to incorporate that in , to measure the amount by which we need to change every weight
:

So, what this means is that by initializing our weights randomly, we will keep them fixed and pass the entire training set through our neural network and generate the outputs for each of the training examples. Then we will compute the error across all of these outputs using our error function and ground-truth labels. For a given learning rate, , the computed
tells us how much we need to change,
, in order to minimize the total error,
, the fastest, as discussed in our previous post on Gradient Descent. Finally, we will add this to the current value of our weight in order to update that weight, using the learning rule:
I am a big fan of simplicity, so let’s give a super simple example. We will define a training set of 2 training data (I know, too small but it is easier to understand). The neural network is the same that is depicted in Fig.1. In this neural network, please note that  is called the bias unit and it is always equal to 1, that is to say
is called the bias unit and it is always equal to 1, that is to say  . As a result the only input from which we will be able to feed in our training data into the neural network would be through . This means that our training data are 1-dimensional. Moreover, we will have to initialize our 2 weights randomly as well and define a learning rate. Finally, in our training set, for every training data, we will also have a ground-truth, so that we could actually compute the error and update the weights in the network. So, all of these are defined as follows:
. As a result the only input from which we will be able to feed in our training data into the neural network would be through . This means that our training data are 1-dimensional. Moreover, we will have to initialize our 2 weights randomly as well and define a learning rate. Finally, in our training set, for every training data, we will also have a ground-truth, so that we could actually compute the error and update the weights in the network. So, all of these are defined as follows:
- Training Data:
=1 and
=2
- The Ground Truth:
=-1 and
=1
- The weights of the neural network are initialized randomly:
=0.01 and
=0.05
- Finally let’s set the learning rate:
=0.01
Now we will input every data point into the network according to Fig.1, compute the outputs  , and compute the error for each of the outputs. This is called the forward-pass phase where the data travels from the input’s side to the output’s side of a neural network.
, and compute the error for each of the outputs. This is called the forward-pass phase where the data travels from the input’s side to the output’s side of a neural network.
In all of the following derivations,
is the
,
, and
, represent the output, ground-truth, and error value for the

So, we have computed the individual errors, summed them, and divided them by 2, and computed the total error. Now for each of the 2 weights in our network, we will have to compute the gradient of the error according to our derivative rule that we have derived, and then we will multiply the gradient by the learning rate to learn the amount we will have to change the current value of our weights. This is called the Backward phase where we back-propagate the gradients from the output side towards the input side of the network, in order to learn the degree by which we will have to increase/decrease every single weight in our neural network.
Finally we will add this value to the old value of our weights, to compute their new values. This is called LEARNING! We are learning the weights based on the errors that we make for every training data! Now, let’s update :

Figure 5: The Backward-Pass where we Compute the Gradient of the Error with respect to in order to Learn it
You note that the only inputs that we have used for computing the gradients in here, is the bias unit and NONE of the training examples in our training set. Why? Because that is the ONLY input that is connected to and the actual training data that are being inputted to the neural network are connected to and NOT ! So, now we have a new value for our ! Now, let’s update :

Figure 6: The Backward-Pass where we Compute the Gradient of the Error with respect to in order to Learn it
You see that we are using all of our training examples to learn ! And we are NOT using the bias unit as it is NOT connected to ! So, now we have a new value for our .

Author: Mehran
Dr. Mehran H. Bazargani is a researcher and educator specialising in machine learning and computational neuroscience. He earned his Ph.D. from University College Dublin, where his research centered on semi-supervised anomaly detection through the application of One-Class Radial Basis Function (RBF) Networks. His academic foundation was laid with a Bachelor of Science degree in Information Technology, followed by a Master of Science in Computer Engineering from Eastern Mediterranean University, where he focused on molecular communication facilitated by relay nodes in nano wireless sensor networks. Dr. Bazargani’s research interests are situated at the intersection of artificial intelligence and neuroscience, with an emphasis on developing brain-inspired artificial neural networks grounded in the Free Energy Principle. His work aims to model human cognition, including perception, decision-making, and planning, by integrating advanced concepts such as predictive coding and active inference. As a NeuroInsight Marie Skłodowska-Curie Fellow, Dr. Bazargani is currently investigating the mechanisms underlying hallucinations, conceptualising them as instances of false inference about the environment. His research seeks to address this phenomenon in neuropsychiatric disorders by employing brain-inspired AI models, notably predictive coding (PC) networks, to simulate hallucinatory experiences in human perception.



Responses