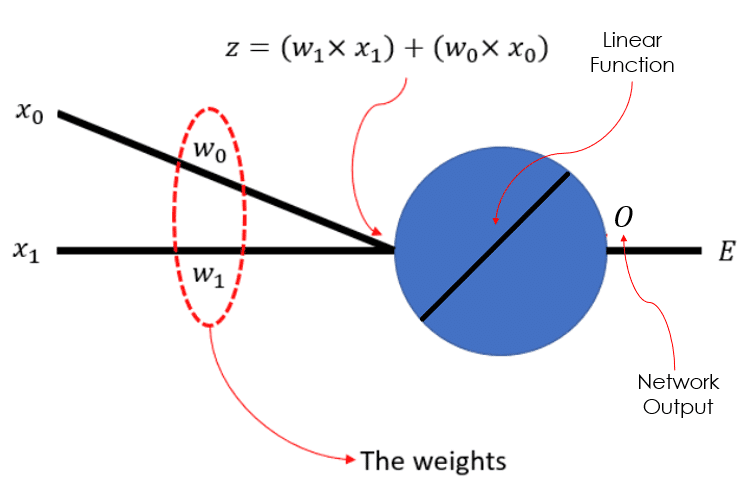
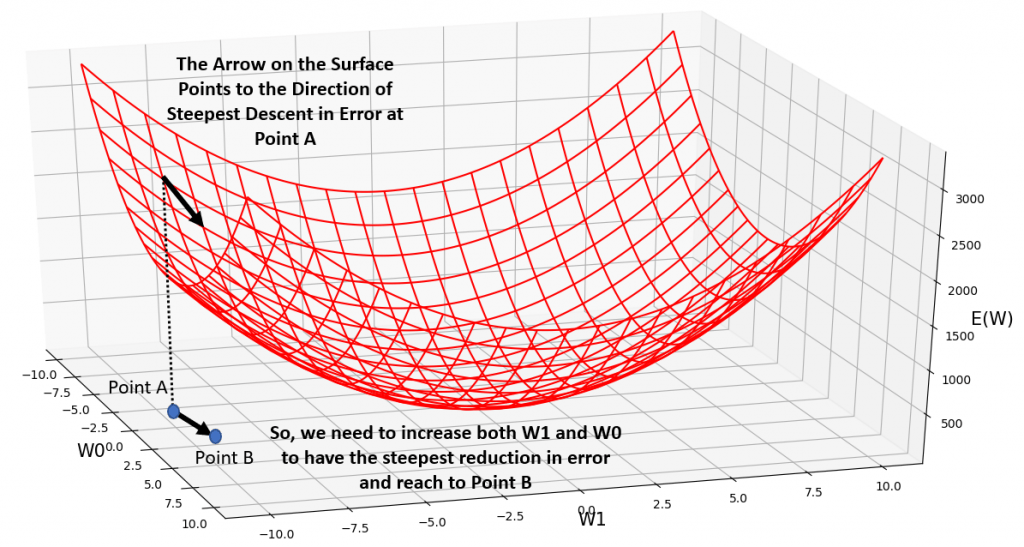
In Fig.3 below, you can see the plooted surface of our SSE error function for a synthetic dataset, across a wide range of possible weight values for our simple neural network, depicted in Fig.1. You can see that it clearly has a global minimum, and that minimum my friends, happens at a specific value for w0 and a specific value for w1. Any other value for w0 and w1 would correspond to a higher error value on the error surface. Note that while training a neural network, we rarely have a nice behaving error surface such as this one. It tends to be wobbly with loads of local maximums and and minimums. However, this is not the topic of this post ;-). It is important, for now, to appreciate the fact that:
Given the way we have defined the error function, for linear units, the error surface is always a parabolic with a single global minimum.
Typically, before gradient descent would start to even explore the hypothesis space of possible weights for the neural network, we would have to initialize our weights to some random values. Let’s say we have chosen the values -5.0 and -10 for w0 and w1 respectively. Notice Point A in Fig.3, on the W0-W1 plain which corresponds to this randomly initialized set of weights. The corresponding error, on the error surface reads a value almost close to 3000 (Ignore the little arrows and other stuff for now ;-)). Here is the question:
How should I change w0 and w1, so that the error would reduce the fastest? What is the direction of this steepest descent in error?
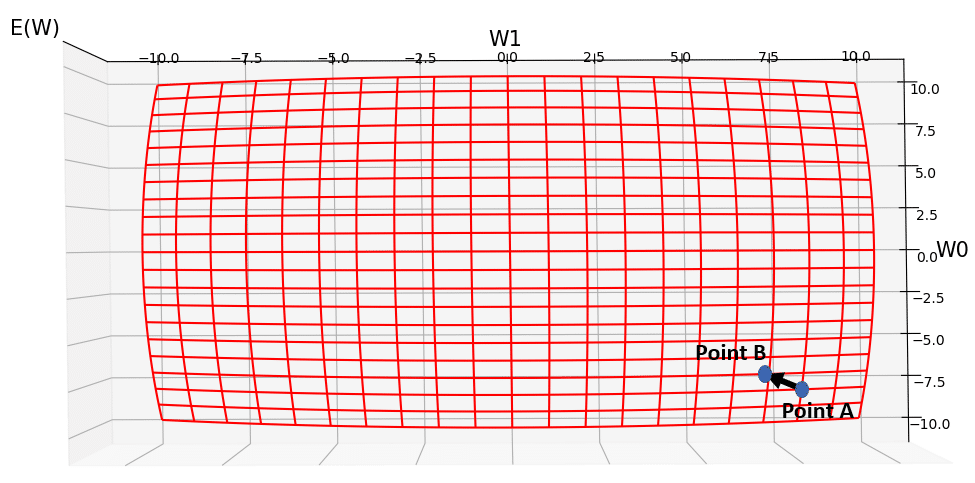
Gradient Descent, searches the hypothesis space of possible weights (i.e., the W0-W1 plain), and finds the direction of the steepest descent in your error, and tells you how much you need to change all of your weights, so that with your new set of weights, you will have had the steepest decrease in your error from the initial old value (3000). The result is moving from Point A to Point B in fig.3. So, after gradient descent took 1 step of optimization, the new set of weights at Point B would be almost 0.0 for w0 and lamost -9.0 for w1. You can see that the new value for error has dropped to nearly 2500. As gradient descent would take more and more steps of finding the direction of steepest descent on in the error surface, the parameters of the model keep updating and updating, until we reach the global minimum. You can see the same error surface from top and bottom views in Fig.4, and Fig.5, respectively.