
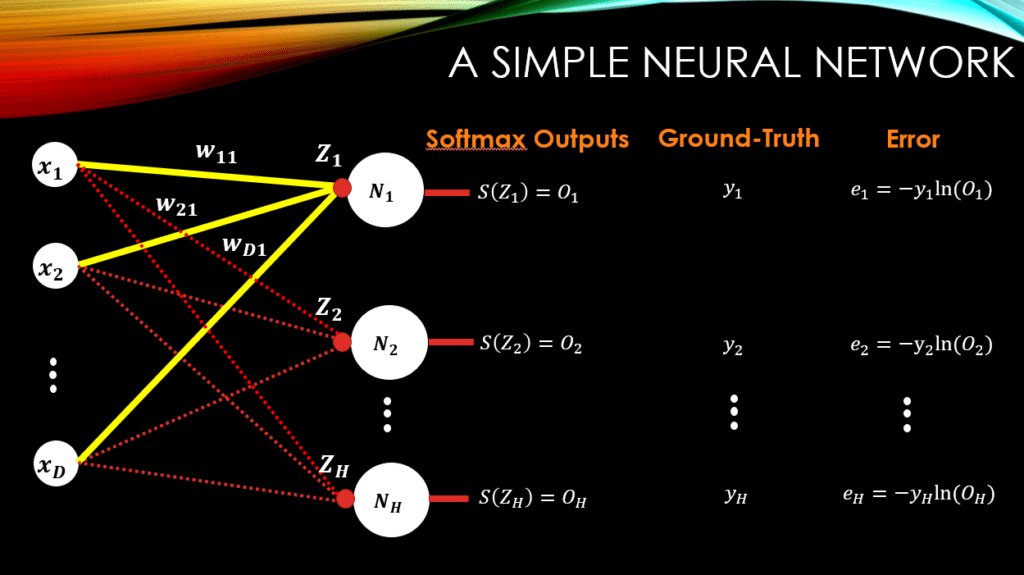
Let’s consider a simple neural network with D-dimensional input data, and output neurons with softmax output function. So, for
output neurons, we will have
softmax outputs. We will have one-hot encoding ground-truth vectors and finally we will have the cross-entropy error function to compute the distance between the output vector and the ground-truth vector. This is a typical neural network for a multi-class classification task. So, for a given training example as the input, the network will generate an output vector with the size of
(which is the number of classes in our dataset)!
So, just as a gentle reminder, the softmax function can be defined as:
And the interesting property of this function is that the sum of all the outputs of softmax, is always equal to 1:
Now, about the ground-truth vector, , we mentioned that it is a one-hot encoding vector. This means that for every ground-truth vector ONLY one element can be equal to 1 and all the other elements are equal to 0!
Finally, regarding the cross-entropy error function, the mathematical representation of this function is as follows:
In this definition of error, , is the natural logarithm. As for an example, let’s say we have 3 output neurons. For a given training example, the output vector of this neural network will have 3 elements in it. Let’s say the output vector is as follows:
You notice that these sum up to 1 as the property of softmax function. And, let’s say the ground-truth vector for the same input training example is as follows:
With s simple comparison between the network output vector and the ground-truth vector you can see that, the network thinks that the given training example belongs to class 2 (as 0.6 is the largest value and corresponds to class 2), however, the ground-truth says that the training example actually belongs to class 1 (as only the value corresponding to the first class is 1 and all the others are 0).
Now, let’s see how we can compute the cross-entropy error function:
which is equal to:
which is:
Now that we are comfortable with the whole setting, let’s see how we can derive the gradient of this error function with respect to the inputs of the softmax output function and apply back-propagation from scratch!
if is a function of
(i.e.,
) and
is a function of
(i.e.,
) then:
You can see that we could easily extend Rule #4 to the natural logarithm where the base of the logarithm is the Euler’s number (i.e., 2.7182 …):
This happens because %20%3D%201) .
.
In order to derive the back-propagation math, we will first have to compute the total error across all the output neurons of our neural network and only then can we start with our derivatives and back-propagation. So, we will sum up all the individual errors,  , for
, for  , and this will be total error across all output units!
, and this will be total error across all output units!
NOTE: In this example, this total error corresponds to the output of the network for ONLY one input training example! Meaning that, if we wanted to compute the error across the whole training examples, we should add another summation to our error computation:
where D is the entire training set. In here,
corresponds to the error value in the
output neuron when the
training example is fed to the neural network.

You can see that we have subtly used Rule #1, in order to take the partial derivative operation into our SUM! And we have also grabbed our ground-truth variable  out of the partial derivative operation, using Rule #2 of independence! Because our ground-truth variable is independent of all the inputs to our softmax layer,
out of the partial derivative operation, using Rule #2 of independence! Because our ground-truth variable is independent of all the inputs to our softmax layer,  ! As a result, we can treat it as an independent variable from
! As a result, we can treat it as an independent variable from
, and bring it out of the partial derivative operation! Finally you notice that we will have to use Rule #3, that is the chain rule!
Why the chain rule? Well because in
, we notice that
is not a direct function of
! In turn,

Now after applying the chain rule, you notice that we have also used Rule #4 to find the derivative of our natural logarithm, that is, . We have got to the place where we will need the derivative of the softmax function w.r.t its input (i.e.,
). We have already covered the derivative of softmax w.r.t its input in our previous post, but as a reminder, see the slide blow:
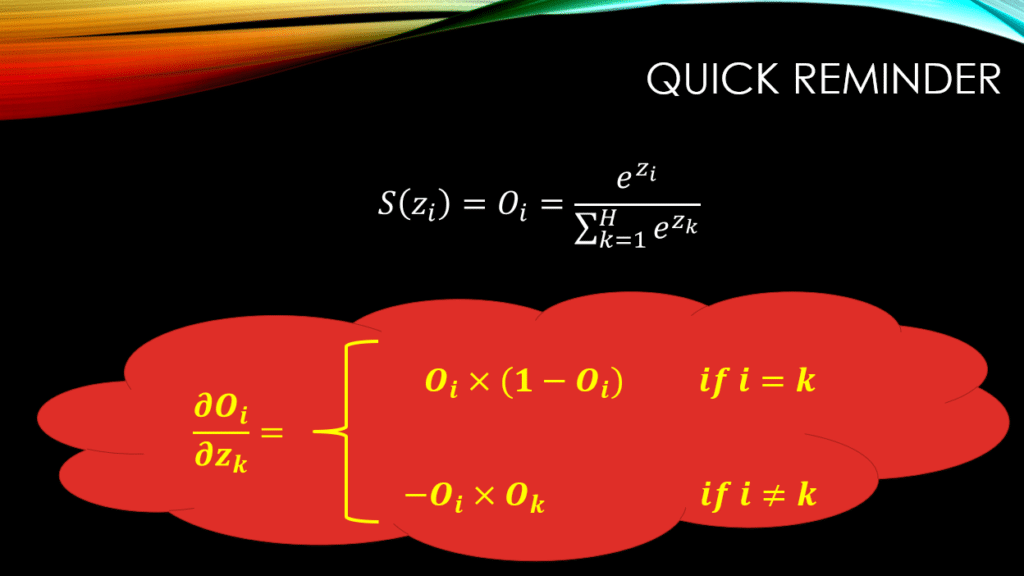
So, we can see that when it comes to  , it all boils down to whether
, it all boils down to whether  or
or  ! As a result, in order to compute , for a given , we will consider all ‘s for
! As a result, in order to compute , for a given , we will consider all ‘s for  ! There will be ONLY one case where , and for all other values of
! There will be ONLY one case where , and for all other values of  , for sure we will have ! Thus let’s solve for both cases:
, for sure we will have ! Thus let’s solve for both cases:

Now, the hard part is over! You can see how we have taken out the term for which ! Then we have used the derivative of softmax (extensively discussed in our previous post) in order to finally be done with the partial derivative operations. Now, let’s simplify:
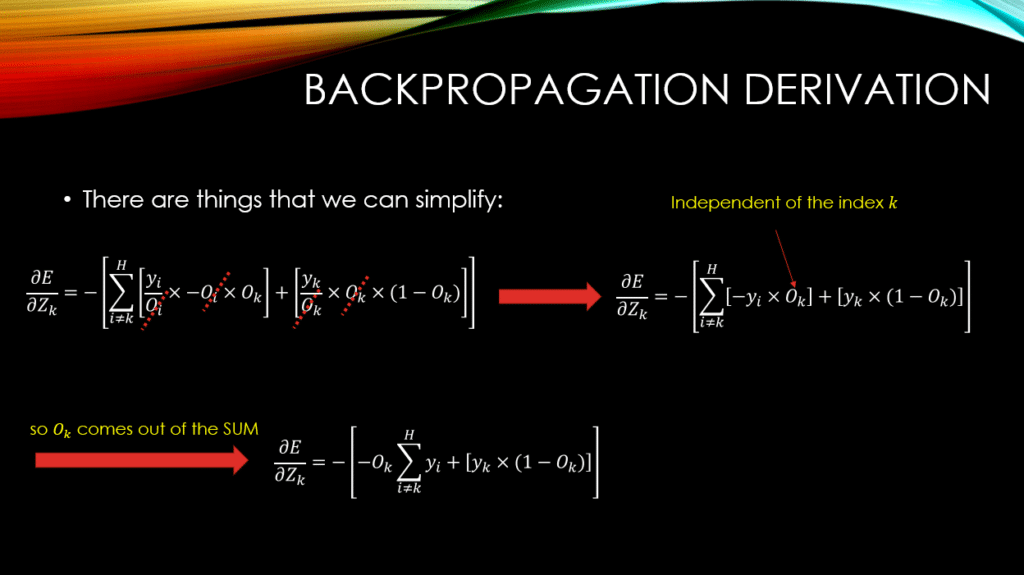
You notice that  has come out of the SUM! The reason is simply because, the index of , is independent of , that is the index over which we are summing! So, is treated as a constant coefficient of !
has come out of the SUM! The reason is simply because, the index of , is independent of , that is the index over which we are summing! So, is treated as a constant coefficient of !
In order to get rid of the summing operation, the next trick we can play is taking advantage of the fact that, the ground-truth vector  , is a one-hot encoding vector! As a result, if we sum all of its elements across all
, is a one-hot encoding vector! As a result, if we sum all of its elements across all  outputs, the result will always be equal to 1 (i.e.,
outputs, the result will always be equal to 1 (i.e.,  ). So, in order to compute
). So, in order to compute  , we can subtract the
, we can subtract the  element of (i.e.,
element of (i.e.,  ), from
), from  . This is how we will get rid of the SUM from our math! See below:
. This is how we will get rid of the SUM from our math! See below:

So, now that we have computed with our smart approach, let’s replace it in our derivations, and simplify more:


Great tutorial and explanation! Only thing i would fix are the images (equations) showing the rules of partial derivatives. They are overlapping the text
Thanks for the feedback. Duely noted!
Great explanation!
I am glad it was helpful 🙂
This is by far the best explanation on the internet. I’ve spent like 3 hours looking for answers and every website or video I’ve come by has repeatedly done incomprehensible shortcuts that convolute the process so much. This was a very by the textbook, simple derivation. Longer but way more understandable.
My suffering was identical to your when I was learning about this topic! This was the main reason why I created this tutorial!
Hi, thanks for the explanation, really clear and easy to follow. However, I don’t understand why we are calculating the derivative of the loss w.r.t. the softmax, instead of calculating the derivative of the loss w.r.t. the weights.
Here is the catch! The only way you can compute the derivative of lthe loss w.r.t the weights, is to go through the softmax function (according to the Chainrule).
I am doing a DataScience course, and apart from the uses of Softmax in classification problems, no-one talks anything more about it. Having understood back propagation to a reasonable extent on YT and such, I was very curious on how it works with Softmax, and this article explained it pretty clearly. Apart from Softmax, I am also interested in understanding the mechanics of MaxPool, Dropout, BatchNormalization, specifically wrt back propagation, any pointers?
Cool! Please be more specific about your questions 🙂
Finally, I found a good explanation for this topic. Other articles were way too difficult for a beginner like me to understand. Splendid JOB !!
Perfect 🙂